Why Most Industrial AI Pilots Fail to Scale
Why Most Industrial AI Pilots Fail to Scale
The gap between a proof-of-concept and production value is widened by data infrastructure, not algorithm choice. Discover the 5 barriers to industrial scale.
It is a familiar story that plays out in the boardrooms of global manufacturing giants every year. A senior executive visits a major industrial trade show or a Silicon Valley tech briefing. They see a stunning demonstration of a computer vision system that promises to detect microscopic defects with 99.99% accuracy, or an "Autonomous Process Control" engine that claims to optimize energy consumption by 15% out of the box. Inspired, they commission a pilot program at a flagship facility.
Three months later, the results are in: the pilot is hailed as a categorical success. The model worked perfectly on the test datasets. The specific machine used for the validation—typically the newest and most reliable asset in the fleet—is performing at record efficiency. Press releases are drafted, and a "Global Transformation Office" is established to roll out the solution across the remaining 14 plants.
But fast forward three years, and the story takes a dark turn. That same solution has stalled. It hasn't reached the other plants. The "Global Transformation" has become a "Global Frustration." The project is quietly defunded, and the organization retreats back to traditional, manual methods. This is the phenomenon we call Pilot Purgatory.
// DATA_SOURCE: GLOBAL INDUSTRIAL TRANSFORMATION AUDIT // 2025
At LOCHS RIGEL, we have conducted forensic audits on dozens of these stalled initiatives. The conclude is always the same: The problem is almost never the algorithm. The problem is the invisible infrastructure of the plant floor.
Infrastructure is the Intelligence
"An AI model is only as powerful as the data rails it runs on. Scaling requires transitioning from 'Algorithm Creation' to 'Data Orchestration'."
To successfully scale Industrial AI, organizations must move past the "Algorithm First" mindset and confront five fundamental structural barriers that exist in the gap between a single successful machine and a global enterprise capability.
Barrier 1: The Industrial Babel (Data Heterogeneity)
In a controlled pilot environment, you have the luxury of time. Your best data scientists can spend weeks manually "massaging" data tags, mapping registers, and cleaning timestamps from a single Siemens S7-1500 controller. They build a bespoke pipeline that works perfectly for that specific machine at that specific firmware level.
But when you attempt to scale to Plant B, you realize the reality of the industrial landscape: Plant B was built six years earlier and runs on legacy Allen-Bradley SLC 500s. Plant C is a brownfield acquisition that uses a mix of Mitsubishi and Modicon hardware. The data models don't match. The units of measure are inconsistent. The sampling rates vary.
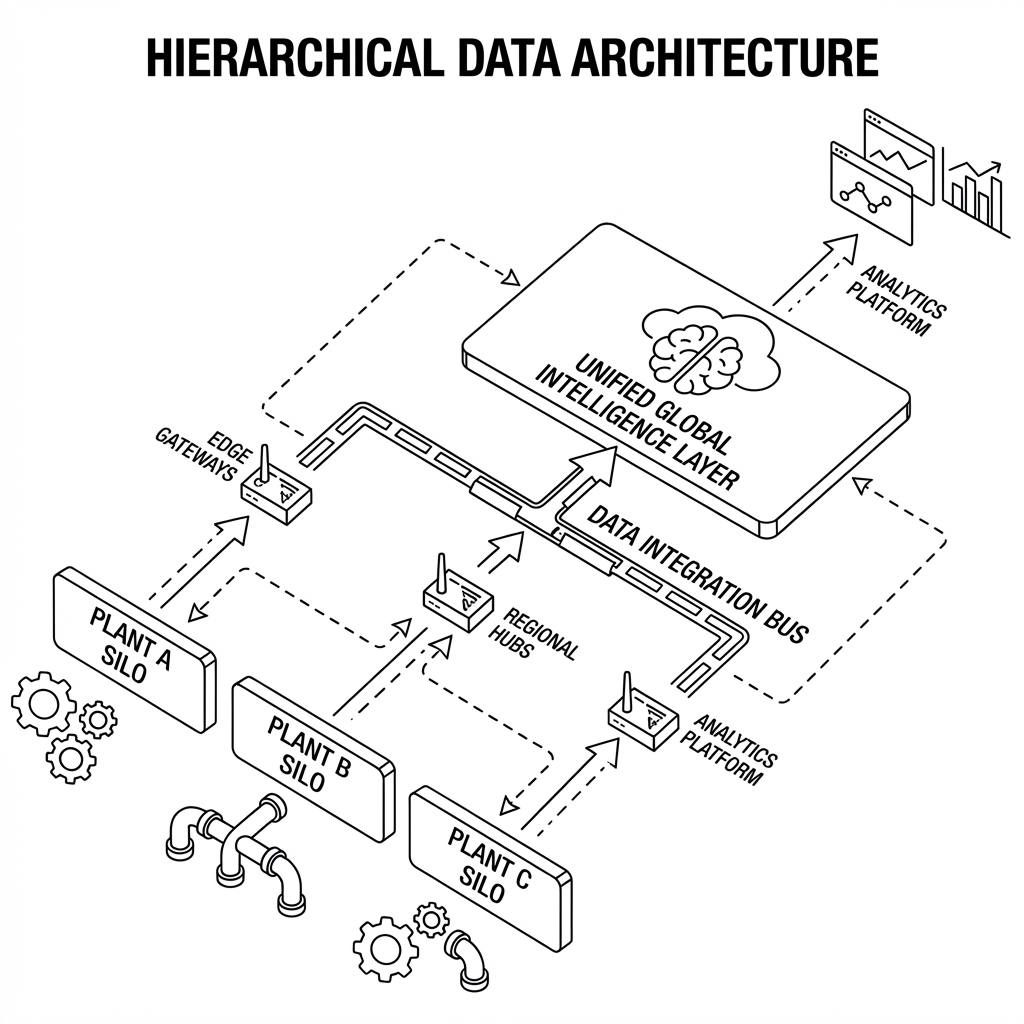
This is the Industrial Babel problem. If your scaling strategy requires a human to manually map data tags for every new factory, you aren't building an AI capability; you are building a massive consulting liability.
The Solution: You must move towards a Unified Namespace (UNS). This is not just a database; it is a hierarchical, event-driven architecture where every asset in the global fleet publishes its data in a standardized, self-describing format (e.g., Site/Area/Line/Machine/Asset). Until your infrastructure can "auto-discover" and "auto-map" assets, you will never scale beyond the pilot.
Barrier 2: The Transition from DevOps to FleetOps
Managing a single NVIDIA Jetson or an edge industrial PC on a test bench is a manageable engineering task. You can manually remote-desktop into the machine, update the container, and check the logs.
Scaling to 500 edge devices across three continents is a different beast entirely. We find that most Industrial AI pilots completely ignore "Day 2 Operations." Scaling requires FleetOps—a discipline that bridges the gap between IT-style cloud orchestration and OT-style physical reliability.
Consider the following scaling challenges:
- Persistent Connectivity: In the cloud, "down" is an emergency. In the factory, "down" or "intermittent" is a Tuesday. Does your AI model degrade gracefully when it loses its link to the central server?
- Security at Depth: How do you push critical firmware patches to an AI gateway that is three firewalls deep in a secure DMZ without violating GxP or IT security protocols?
- Hardware Lifecycle: Who is responsible for the hardware when it fails? If a GPU-accelerated gateway dies at a plant in Vietnam, does the local maintenance team know how to swap it? Does the new device automatically pull the correct model configuration from the cloud?
To scale, you must treat your factory floor as a distributed private cloud, utilizing container orchestration (K3s, Docker, etc.) that allows for "one-click" global deployments with automated rollbacks.
Barrier 3: The "Ground Truth" Bottleneck
Deep learning models are "hungry" for labeled data (Ground Truth). During a pilot, a team of graduate-level engineers can spend a weekend manually labeling 20,000 images of weld defects to train a model. This is physically and economically impossible at scale.
If your ROI depends on expensive humans sitting in an office manually labeling images or tagging anomalies for 100 production lines, your business case will collapse.
The Solution: You must engineer "Closed-Loop Ground Truth." This means integrating the labeling process directly into the operator's workflow. When the AI flags a potential defect, the operator on the floor should be able to "Confirm" or "Reject" the alert with a single tap on a hardened HMI. This interaction then feeds back into the training pipeline as a labeled data point. Success at scale isn't about having the best starting model; it's about having the most efficient feedback loop to improve that model in the wild.
Barrier 4: Cultural Inertia and the "Explainability Gap"
We often overlook the human element of the factory floor. An operator with 25 years of experience knows the "sound" of a machine that is about to fail. If an AI "black box" tells that operator to stop the line because of a predicted failure, but provides no explanation, the operator will likely ignore it.
In a pilot, the technical team is there to explain the results. At scale, the AI must defend itself. This is the Explainability Gap.
To scale, AI must transition to XAI (Explainable AI). If a computer vision system rejects a part, it must highlight the specific pixel-grid that triggered the reject. If a predictive maintenance engine suggests a motor swap, it must show the specific frequency shift in the vibration data that correlates with a known bearing failure pattern. When operators understand the "Why," they build trust. When they build trust, they adopt. Adoption is the only true measure of scale.
Barrier 5: Misplaced Capital (The Ferrari in the Field)
There is a recurring financial error in industrial transformation: firms spend $5M on "AI Strategy" and "Algorithm Development" but only $200k on the actual sensors, cabling, and compute needed to feed the model.
This is like buying a Ferrari engine and trying to install it in a horse-drawn carriage. The engine is spectacular, but the carriage cannot handle the torque, the fuel delivery is non-existent, and the wheels will fall off at 20 mph. At LOCHS RIGEL, we believe this pursuit is not just academically misguided, but operationally hazardous. In the high-stakes world of precision manufacturing—where microns, milliseconds, and thermal gradients determine EBITDA—the factory floor is governed by the unyielding laws of thermodynamics, not the statistical probability of a linguistic string.
// DATA_SOURCE: PRECISION MANUFACTURING YIELD SNAPSHOT // 2025
The Hardware-Intelligence Paradox
"You cannot automate what you cannot measure. Over-investing in AI while under-investing in sensor fidelity ensures your 'intelligence' stays blind to physical reality."
Scaling requires a Balanced Capital Stack. High-performance intelligence requires high-fidelity sensing. If your sensors are 20 years old and your network is still running on legacy daisy-chained serial cables, your AI will be "blind." You cannot automate what you cannot measure, and you cannot scale what you cannot see accurately.
The LOCHS RIGEL Execution Framework
How do you break the cycle of Pilot Purgatory? We advise our clients to follow a "10-20-70" resource allocation model:
- 10% for the Algorithms: Use off-the-shelf, proven models where possible. Don't waste capital inventing new math when the industry has already optimized the models.
- 20% for the Data Infrastructure: Build the Unified Namespace. Sanitize your tags. Harden your edge compute.
- 70% for the Business Process & Scale: Focus on the "Day 2" operations, the operator training, the FleetOps orchestration, and the integration of AI into the actual P&L of the plant.
The Walkaway: Three Critical Questions for the Boardroom
Before you approve the budget for a new "AI Transformation," ask your technical steering committee these three questions:
- "Show me the Unified Namespace." Is the data standardized? If we acquire another company tomorrow, how long will it take to onboard their machines into this AI model?
- "Who owns the edge hardware?" Do we have a FleetOps plan? What happens when a device in a remote facility fails at 3:00 AM?
- "How does the operator talk back to the AI?" How are we closing the loop? Does the system get smarter every day based on operator feedback, or are we buying a static artifact that will be obsolete in 12 months?
Scale is an engineering discipline, not a mathematical one. To lead in the next decade, stop looking for the perfect pilot and start building the indestructible foundation.
At LOCHS RIGEL, we don't just build the AI; we build the infrastructure that allows the AI to survive the real world.